
About the Project
Better Feedback for Every
Medical Student in the UT System
This project — "Scaling and Validating AI-Enabled Simulation Assessment Across University of Texas Medical Schools" — is an 18-month, $300,000 initiative funded by the UT REAL Health AI Pilot Program, which supports collaborative, implementation-focused AI initiatives across UT Health-Related Institutions.
How It Works
From OSCE capture to AI grading to faculty review — the end-to-end workflow that turns raw clinical encounters into actionable feedback for students.
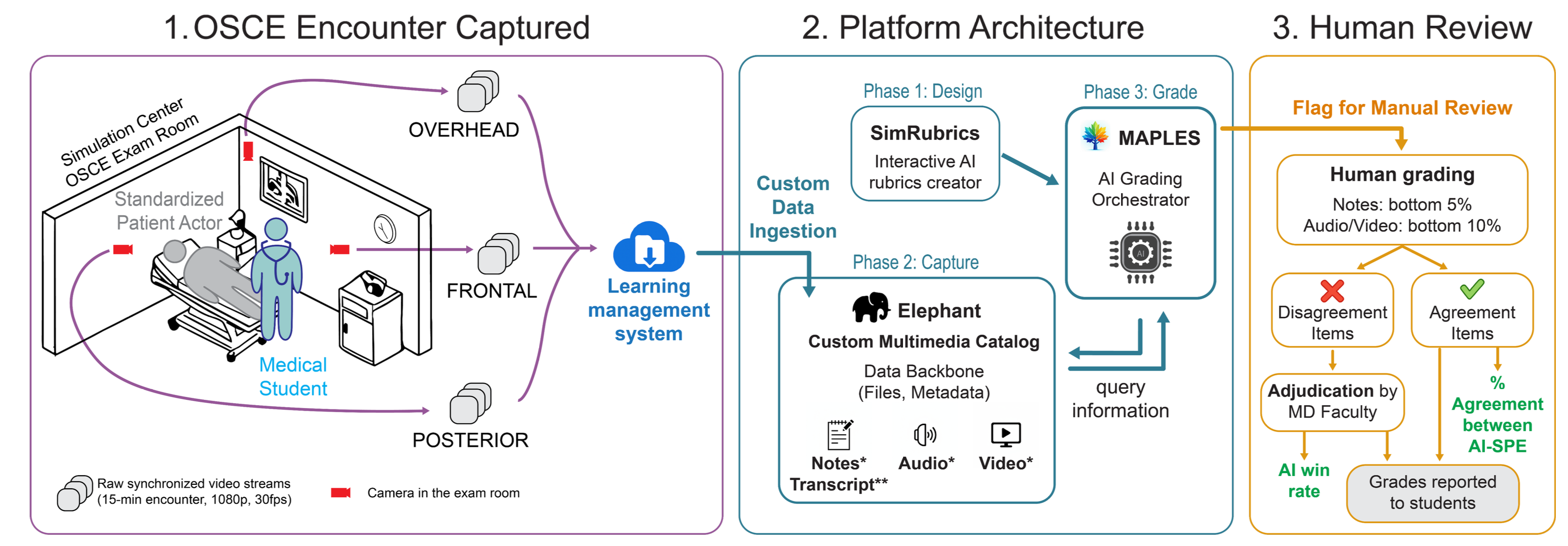
1. Capture — Multi-angle video from the simulation center flows into a learning management system. 2. Platform — SimRubrics authors AI-compatible rubrics, Elephant catalogs the multimedia data, and MAPLES orchestrates AI grading. 3. Review — Faculty review flagged items, adjudicate disagreements, and grades are reported to students with full provenance.
What is an OSCE?
An Objective Structured Clinical Examination (OSCE) is how medical schools assess whether students can demonstrate clinical skills in a standardized medical scenario.
Students are assessed on communication, history taking, physical examination, clinical reasoning, and medical knowledge. They rotate through rooms, each with a standardized patient presenting a different scenario. Every encounter is filmed and graded on a detailed rubric — the gold standard for clinical competency assessment.
The result is an enormous volume of encounters that need expert review. That's where AI comes in.
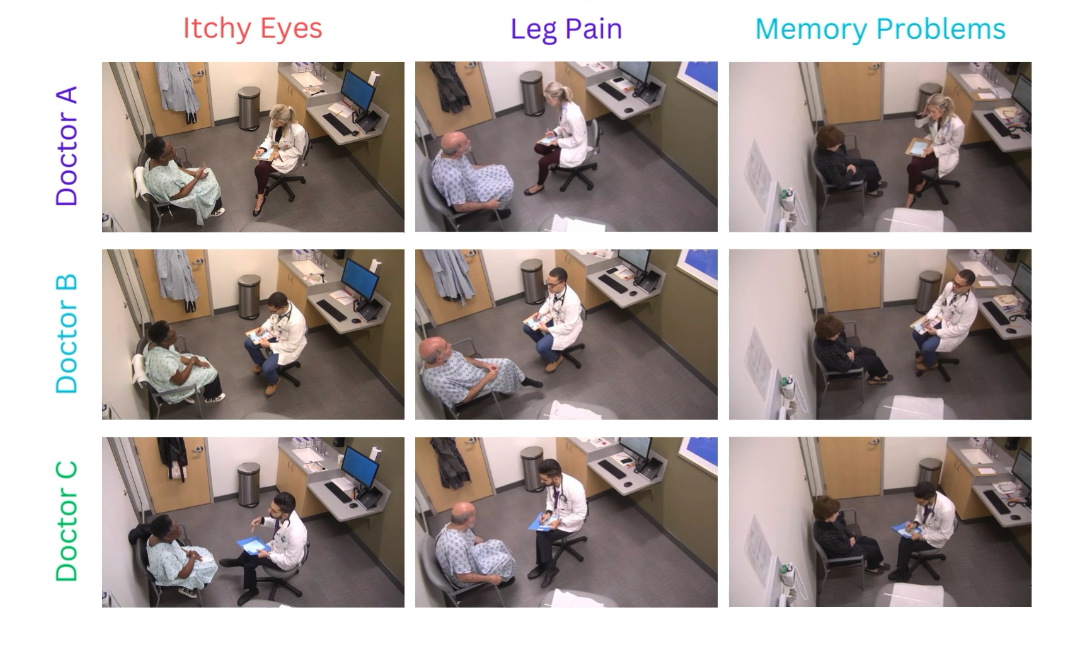
Medical students rotating through OSCE stations — each encounter filmed from overhead cameras and graded on clinical rubrics.
The Challenge
The educators who train tomorrow's doctors deserve better tools.
- 1
Grading Takes Too Long
After every OSCE, faculty and standardized patient educators spend hours manually grading encounters. That delay means students wait days or weeks for feedback — and timely feedback is what changes clinical behavior.
- 2
Graders Disagree With Each Other
Even well-trained human raters produce inconsistent scores (kappa = 0.732 at UTSW). Grade compression, fatigue, and differences in rubric interpretation mean students may get different grades depending on who reviewed them.
- 3
Every School Is on Its Own
Medical schools grade in isolation with no shared tools, benchmarks, or infrastructure. There is no easy way to learn from each other's assessment practices or adopt what works at peer institutions.
Our Approach
The MAPLES Platform
AI that helps educators give students faster, more consistent, and more detailed feedback on their clinical skills.
More Consistent Than Human Graders
MAPLES achieves kappa = 0.830 agreement with expert raters — higher than human inter-rater reliability (kappa = 0.732). Faculty retain final authority; AI handles the routine so educators can focus on the cases that need their judgment.
Three Years in Production
7,000+ encounters graded across 3,200+ students at UTSW. Not a research prototype — a working tool that faculty rely on for both formative and summative assessments every academic cycle.
Planned Centralized Infrastructure via UT-HIP
UT-HIP engagement is underway as the preferred centralized infrastructure path, with final hosting, governance, and access controls to be determined through site-specific approvals.
Multimodal Assessment
Beyond text-based note grading: the platform supports audio, transcript, and video analysis for physical examination identification and clinical reasoning assessment.
Flexible Rubric Framework
AI-compatible rubric design that each school can customize to their own educational philosophy — shared tools and best practices, not one-size-fits-all templates.
Open Governance Playbook
Developing a reusable framework for multi-site IRB routing, data use agreements, and AI governance in medical education — designed for adoption beyond the UT System.
By the Numbers
Production metrics from UTSW — the foundation we're scaling across the UT System.
Guiding Principles
The values that shape how we build and deploy AI in medical education.
- 1
Human-in-the-Loop
AI augments, not replaces, expert judgment. Faculty review flagged encounters and retain final authority over grades. The bottom ~20% of AI confidence scores trigger mandatory human review.
- 2
Phased Deployment
Sites activate at their own pace along two axes: modality (text → transcript → video) and study design (retrospective → prospective). No site is forced into lockstep.
- 3
Transparency and Reproducibility
Every AI grading decision is logged with full provenance. Rubric versions, model parameters, and confidence scores are captured for audit and research.
Funding & Support
This project is one of several initiatives funded by the UT REAL Health AI Pilot Program ($300,000, awarded March 2026, 18 months). Infrastructure is supported by the UT Health Intelligence Platform and UT Southwestern Enterprise Data Services. The project originated at the UTSW Simulation Center, built by the Jamieson Lab.